Week 1
JVM & JRE

Primitive data types vs. Non-primitive data types
-
There are 8 primitive data types:
Logical: boolean
Textual : char
Integral: byte, short, int, long
Floating point: double, float
-
Non-primitive (reference) data types: The non-primitive data types include Strings, Classes, Interfaces, and Arrays
The difference between primitive and non-primitive data types are as follows:
- Primitive types are predefined in Java. Non-primitive types are created by the programmer and is not defined by Java.
- Non Primitive types can be used to call methods to perform certain operations, while primitive types cannot.
-
A primitive type always has a value, whereas non-primitive types can be null.
- The size of a primitive type depends on the data type, while non-primitive types have all the same size.
- All the data for primitive type variables are stored on the stack whereas, for reference types, the stack holds a pointer to the object on the heap.
String literal vs. String
String Literal is a String created using double quotes while String Object is a String created using the new() operator.
The string literals are always stored in the string pool. When a string literal is created, the pool is checked to see if there is already a string literal having the same value. If found, the reference to that string is returned. If not found, a new string is created in the pool and its reference is returned.
When you create a String object using the new() operator, it always creates a new object in heap memory.
Local variables, Instance variables, Static variables
-
A variable defined within a block or method or constructor is called a local variable. Local variables are allocated on the stack when execution reaches the block and they are deleted when execution leaves the block. In other words, we can access local variables only within the block in which the variable is declared.
Initialization of the local variable is mandatory before using it in the defined scope.
-
Instance variables are non-static variables and are declared in a class outside any method, constructor, or block. These variables are created when an object of the class is created and destroyed when the object is destroyed. Initialization of instance variable is not mandatory.
-
Static variables are declared using the static keyword within a class outside any method constructor or block. Static variables are created at the start of program execution and destroyed automatically when execution ends. Initialization of static variable is not mandatory.
Differences between the Instance variable vs. the Static variables:
- Changes made in an instance variable using one object will not be reflected in other objects as each object has its own copy of the instance variable. In the case of static, changes will be reflected in other objects as static variables are common to all objects of a class.
- We can access instance variables through object references. Static variables can be accessed directly using the class name.
Stack vs. Heap
The major difference between stack memory and heap memory is that the stack is used to store the order of method execution and local variables while the heap memory stores the objects and it uses dynamic memory allocation and deallocation.
Each time we call a method, Java allocates a new block of memory called stack to hold its local variables.
Whenever we create a new object, Java allocates space from a pool of memory called the heap.
Upcasting vs. Downcasting
Upcasting: Upcasting is the typecasting of a child object to a parent object. Upcasting can be done implicitly.
Parent p = new Child();
Downcasting: Downcasting is the typecasting of a parent object to a child object. Downcasting cannot be implicit. Downcasting can be useful to get a reference with proper static type (therefore, do all operations/access all members). It is necessary to first check this cast is allowed by using the keyword instanceof.
Child c = (Child) p;
Week 2
What is object-oriented programming
Object Oriented programming (OOP) is a programming paradigm that relies on the concept of classes and objects. It is used to structure a software program into simple, reusable pieces of classes, which are used to create individual instances of objects.
Overloading vs. Overriding
When two or more methods in the same class have the same name but different parameters, it’s called Overloading.
When the method signature (name and parameters) are the same in the superclass and the child class, it’s called Overriding. Overriding a method means to redefine a new version of the method down in the hierarchy.
Return type can be same or different in method overloading. But you must change the parameter. Return type must be same or covariant in method overriding.
Fundamental characteristics of OO language
Encapsulation: The whole idea behind encapsulation is to hide the implementation details from users. Encapsulation shields the data members from unwanted access. To achieve this, we specify the modifiers of data members as private and setup public methods, for example, getter and setter, to read and write the private data fields. Then the outside class can access those private data fields via certain public methods.
Encapsulation makes the code much more maintainable: a code using a certain class will continue to work even if the class implementation changes (but not its interface).
Inheritance: The process by which one class acquires the properties (data members) and functionalities (methods) of another class is called inheritance. The class that extends the features of another class is known as child class. The class whose properties and functionalities are inherited by another class is known as parent class. The aim of inheritance is to provide the reusability of code so that a child class writes only the unique features and rest of the common properties and functionalities can be extended from the parent class.
Polymorphism: Polymorphism allows us to perform a single action in different ways. It occurs when we have many classes that are related to each other by inheritance. A superclass named Shapes has a method area(). Subclasses of Shapes can be Triangle, Circle, Rectangle and so on. Each subclass has its way to calculate area. Using Inheritance and Polymorphism means, the subclasses can use the area() method to find the area’s formula for that shape.
Week 3
Static vs. Dynamic type
The static type (ST) of a reference is the declaration type.
The dynamic type (DT) of a reference is the type of the actual object This relation always holds: DT(ref) ≤ ST(ref). The static type of a reference cannot change during the execution. The dynamic type can.
Abstract class & Interface
A class which declares some methods but does not specify their implementations is called abstract. It is not possible to instantiate an object of an abstract class: these classes must be extended by concrete classes which implement all abstract methods. It is possible to declare reference referring to an abstract class.
An interface is, basically, a class with all methods abstract. An interface can have only static final (i.e., constant) data fields and static methods. A class can extend one class but can implement several interfaces
UML
The Unified Modeling Language is a general-purpose, developmental, modeling language in the field of software engineering that is intended to provide a standard way to visualize the design of a system.
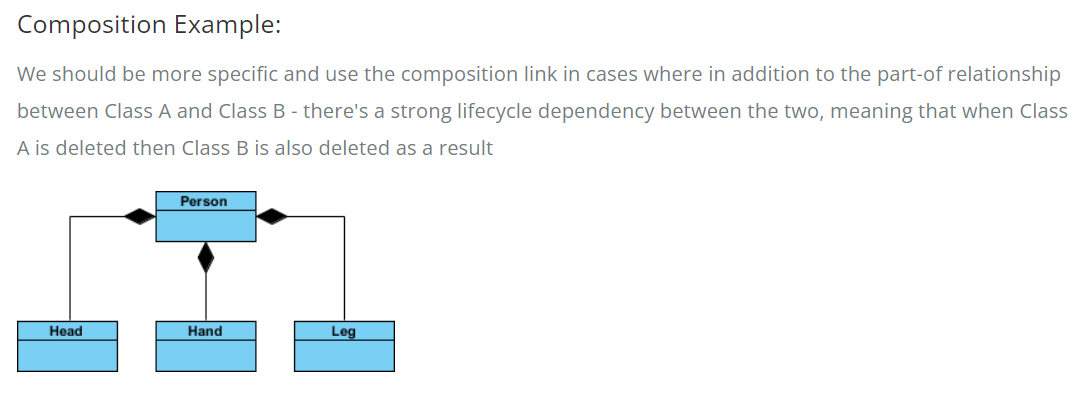
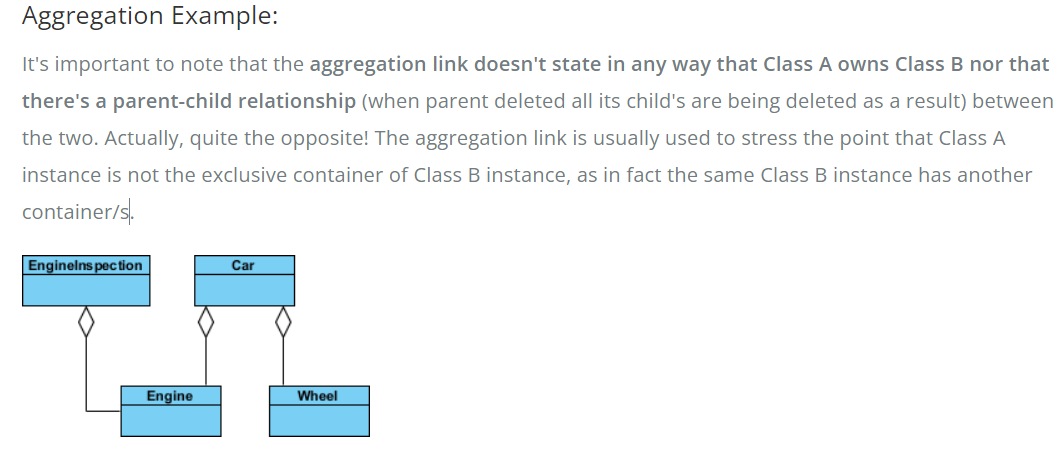
Aggregation implies a relationship where the child can exist independently of the parent. Example: Class (parent) and Student (child). Delete the Class and the Students still exist. Composition implies a relationship where the child cannot exist independent of the parent. Example: House (parent) and Room (child). Rooms don’t exist separate to a House.
Week 4
SOLID principles
-
Single responsibility principle: A class should only have one reason to change.
If a class has more than one responsibility, then the responsibilities become coupled. Changes to one responsibility may impair or inhibit the class’ ability to meet the others. Violating the single responsibility principle results in fragile design that can break in unexpected ways.
-
Open closed principle: Software entities should be open for extension, but closed for modification.
Behavior should be added by adding new code, not by changing the old one. Abstraction through interfaces and abstract classes is key.
-
Liskov substitution principle: Derived classes must be substitutable for their base classes.
Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.
-
Interface Segregation Principle: Make fine grained interfaces that are client specific.
It is risky to depend upon “fat” or “polluted” interface, because fat interfaces are not cohesive.
-
Dependency inversion principle: Depend on abstractions, not on concretions.
High-level code should not depend on low-level code. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.
verification vs. validation
Verification: Are we building the product right?
Verification is a process that determines the quality of the software. Verification includes all the activities associated with producing high quality software. For example, testing, inspection, design analysis, specification analysis, and so on. Verification helps in lowering the number of the defects that may be encountered in the later stages of development.
Validation: Are we building the right product?
Validation is the process of checking whether the software meets the requirements and expectations of a customer. it checks what we are developing is the right product. it is validation of actual and expected product. Validation is done during testing like unit testing, integration testing, system testing, compatibility testing and so on.
The difference between verification and validation is as follow:
- Validation comes after verification.
- Validation is the process of checking whether the software meets the customer’s requirements, while verification is the process of checking whether the software meets the specifications.
- Validation is a subjective process. It involves making subjective assessments of how well the system addresses a real-world need. In contrast, verification is a relatively objective process. It includes all the activities associated with the producing high quality software.
Black-box vs. White box testing
Black-box testing (Functional Testing) is a software testing method in which the internal structure/design/implementation of the item being tested is not known to the tester. Tests are based on requirements and functionality.
- Equivalence class testing is applied to test the method
robotInteraction()of the charger. This method can give one life to the robot, but the life of the robot will never go below 1 or exceed 5.- Identify the entire input data space of the unit under test. It is integers from 1 to 4.
- Partition this input space into different equivalence classes. The valid inputs are integers from 1 to 4. The invalid inputs are all integers less than 1 or greater than 4.
- Select a data element from each equivalence class and test the unit using this input. For example, -10, 3, 50. The hypothesis behind this technique is that if one data element in a class passes, all others in this class will also pass.
- Check that the output is as expected. It should be invalid, 4 and invalid.
- For Boundary condition analysis, instead of checking one value for each class, we tested values at both valid and invalid boundaries. They are 0, 1, 2, 3, 4, 5.
White-box testing (Structural Testing) is a software testing method in which the internal structure/design/implementation of the item being tested is available to the tester. Tests are based on coverage of code, statements, branches, paths, and conditions.
if (score < 50) {
...
} else {
...
}
if (score >= 90) {
...
}
- Statement Coverage: All the executable statements in the source code are executed at least once. If we look at the flow chart, all the nodes are covered. (45, 93)
- Branch Coverage: Every outcome from a code module (statement or loop) is tested. If we look at the flow chart, all the edges are covered. (45, 93)
- Every possible execution path of some code is test. If we look at the flow chart, all the paths from start to end are covered. (45, 93, 55)
In our project, we used scenario outline to run the same scenario multiple times with different inputs to test all the possible cases. For this scenario, we can add 3 rows to cover all the possible paths of the unit.
Regression testing
Regression: When a feature that used to work, no longer works.
Regression testing: Re-executing prior unit tests after a change. Regression testing is typically automated using testing frameworks like JUnit. Regression testing helps to ensure changes or bug fixes do not break previously working parts of the code.
Unit testing: used to look for errors in a subsystem in isolation
Week 5
Generics
Whenever it is necessary to parametrize a class or a method with respect to the type (rather than the values) we can use generics
For example, define a class containing a homogeneous pair of elements. When we instantiate an object of type Pair we are required to specify the generic type.
public class Pair <T> {
private T first;
private T second;
}
Pair<Integer> pInt = new Pair<Integer>(42, 21);
Pair<String> pStr = new Pair<String>("Alice", "Bob");
BDD vs. TDD
Test-driven development typically involves writing a test for a certain piece of functionality, running the test to see it fail and then writing the code to make the test pass.
That way, developers can be confident that they’ve written code that does the job and other developers reusing components can run the test to be confident that their own code will properly function.
Behavior-driven development typically involves a developer, test engineer and a product manager (and potentially other stakeholders). The group meets to come up with concrete examples of acceptance criteria in a user story. These examples are put into a feature file. The feature file is converted into an executable specification where developers can then write an actual executable test.
Week 8
Design patterns
-
The Observer pattern defines a one to many dependency between objects so that one object changes state, all of its dependents are notified and updated automatically. Observer affords a loosely coupled interaction between subject and observer. This means they can interact with very little knowledge about each other.
-
The Simple factory pattern describes a class that has one creation method. The method parameters decides which kind of product to instantiate and then return it. This allows interfaces for creating objects without exposing the object creation logic to the client.
-
The Singleton pattern ensures a class has only one instance (or a constrained set of instances), and provides a global point of access to it. The key is to limit access to the constructor of the class, such that only code in the class can invoke a call to the constructor.
-
An Adapter pattern acts as a connector between two incompatible interfaces. An Adapter wraps an existing class with a new interface so that it becomes compatible with the other interface.
-
The Facade Pattern provides a unified interface to a set of interfaces in a subsystem. Client code is simplified and the client’s dependencies are greatly reduced. A facade not only simplifies an interface, it decouples a client from a subsystem of components.
Both facades and adapters may wrap multiple classes, but a facade’s intent is to simplify, while an adapter’s is to convert between interfaces.
Week 9
Version control
Version control, is the practice of tracking and managing changes to software code. Version control systems are software tools that help software teams keep tracking of changes, integrate versions, recognize conflicts. It also allows for recovery and documentation of changes.
Centralized version control systems (such as CVS, Subversion, and Perforce) have a single server that contains all the versioned files, and a number of clients that check out files from that central place.
This setup offers many advantages, especially over local VCSs. For example, everyone knows to a certain degree what everyone else on the project is doing. Administrators have fine-grained control over who can do what, and it’s far easier to administer a CVCS than it is to deal with local databases on every client.
However, this setup also has some serious downsides. If that server goes down for an hour, then during that hour nobody can collaborate at all or save versioned changes to anything they’re working on. If the hard disk the central database is on becomes corrupted, and proper backups haven’t been kept, you lose absolutely everything
In distributed version control (such as Git, Mercurial), clients don’t just check out the latest snapshot of the files; rather, they clone a copy of the repository and have the full history of the project on their own hard drive.
Thus, if any server dies, any of the client repositories can be copied back up to the server to restore it. Furthermore, many of these systems deal pretty well with having several remote repositories they can work with, so you can collaborate with different groups of people in different ways simultaneously within the same project.
Continuous Integration
Continuous integration fosters a sense of always being production ready: you always have a functioning system. Developers add features incrementally and always ensure that the system can run.
To adopt continuous integration you need:
- A source code repository (the source code repository - Git)
- A check-in process (Run all tests and ensure that all of them pass)
- An automated build process (an automated build tool - Maven)
- Willingness to work incrementally (Integrate new code into the system in small chunks)